◎本特許のまとめ
・ランキングスコアは、ヒストリデータに(一部)基づいて算出される
・ヒストリデータには、ドキュメント(ページ)作成日、コンテンツの更新/変更、クエリ分析、リンクベース基準、アンカーテキスト、トラフィック、ユーザーの行動、ドメイン情報、ランキング履歴、ユーザー保存データ、トピックスなどを含む
◎この特許について
・Googleのページランクに関する特許です。ページランクに関する特許は多数ありますが、その一つです。SEOの参考になれば幸いです。
・本特許は古いものですが、多くの特許の基となった米国特許、US7346839の流れを汲む特許のため取り上げました。
・この特許出願自体は取下げとなっていますが、同系列(同じファミリ)の特願2007-001794、特願2011-027886がいずれも特許になっています。これらもいずれ解説したいと思います。
・本特許の内容が、現在の検索アルゴリズムに用いられているとは限りませんのでご注意ください。
◎書誌的事項
【公開/特許番号】特表2007-507798
【国際出願番号】PCT/US2004/030000
【優先日】2003.09.30
【出願日】2004.09.15
【発明の名称】ドキュメントをスコア付けするための方法、ドキュメントをランク付けするための方法及びドキュメントをスコア付けするためのシステム
【発明者】ACHARYA, ANURAG, ; CUTTS, MATT, ; DEAN, JEFFREY, ; HAAHR, PAUL, ; HENZINGER, MONIKA, ; HOELZLE, URS, ; LAWRENCE, STEVE, ; PFLEGER, KARL, ; SERCINOGLU, OLCAN, ; TONG, SIMON
【国際特許分類】G06F17/30
【特許出願の帰結】取下げ
◎内容解説
※オリジナルの特許ではdocuments(web documents)という言葉が用いられていますが、これは、特許の権利範囲を考慮して割り当てられた用語と考えます。よって、本特許を理解するに際しては、「ドキュメント」という用語を「(ウェブ)ページ」や「(ウェブ)サイト」と読み替えて頂くと理解しやすいと考えます。
※細部を省略していますので、細部については原文をご参照ください。
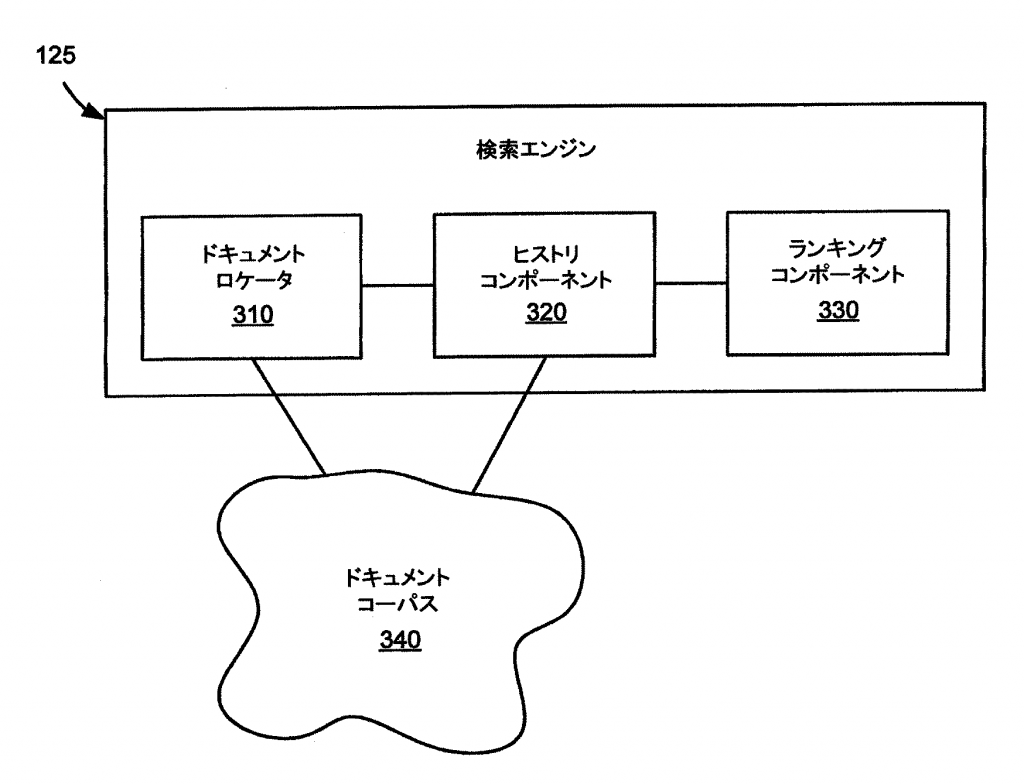
まず、上記の図の解説です。
・ドキュメントロケータ310:ユーザの検索(クエリ)に適合するコンテンツを含むページを特定する構成要素。
・ヒストリコンポーネント320:(ドキュメントコーパス340中のドキュメントに関連付けられた)ヒストリデータを収集する構成要素。
・ランキングコンポーネント330:ランキングスコア(単にスコアとも呼ぶ)をドキュメントコーパス340中のドキュメントに割り当てる構成要素。
・ドキュメントコーパス340:検索エンジン125にアクセス可能なデータベースに格納された、ドキュメント(ページ)関連の情報体。
今回の主役はヒストリコンポーネント320です。
ランキングスコアは、ヒストリコンポーネント320からのヒストリデータ(の一部)に基づきます。
そして、ヒストリデータとは、例えば以下のものを含みます。
①ドキュメント作成日(documents inception date)
②コンテンツの更新/変更
③クエリ分析
④リンクベース基準
⑤アンカーテキスト
⑥トラフィック
⑦ユーザーの行動
⑧ドメイン情報
⑨ランキング履歴
⑩ユーザーによって保存/生成されたデータ(例:ブックマーク)
⑪アンカーテキスト中のユニークワード、バイグラム、フレーズ
⑫独立したドキュメント(ページ)からのリンク/(ページ)への リンク
⑬ドキュメントトピックス
端的に言うと、これらの要素がページランクに関係します。
要点は以上です。
以下では、ヒストリデータに係るこれらのデータについて、解説します。
☆ ☆ ☆
①ドキュメント(ページ)作成日
通常、最近のドキュメントは、より多数のリンク(バックリンク)を有するより古いドキュメントよりも低くスコア付けされ得る。
しかしながら、ドキュメントの作成日を考慮して、ドキュメントのスコアは(肯定的か否定的に)修正され得る。
・ドキュメント作成時は、例えば検索エンジンが認識するかインデックスした日によって決定される。あるいは、別のページから参照された日でも良い。
・ドキュメントのリンクに基づくスコアは、例えば以下のように修正されても良い。
H=L/Log(F+2)
H:ヒストリ調整後のリンクに基づくスコア
L:調整前のリンクに基づくスコア
F:ドキュメント作成時からの経過時間
※なお、作成日が古い方が良いとか、新しい方が良いとかではありません。ケースバイケースです。
②コンテンツ更新/変更
時間経過に伴うコンテンツ変更情報は、スコア生成(変更)に使用され得る。
・検索エンジンは、例えば以下のようなコンテンツ更新スコア(U)を生成できる。
U=f(UF,UA)
UF:更新頻度スコア
UA:更新量スコア
即ち、更新スコアはコンテンツ更新頻度・更新量に拠る。
ここで、更新量スコアUAについて以下のようなことが考えられる。
1.Javaスクリプト、コメント、広告、ナビゲーション要素、テンプレート素材、あるいは日付/時間タグといった、更新/変更されても重要でないとみなされるコンテンツは、比重が相対的が小さいか、無視される。
2.前方リンクに関連付けられたタイトルやアンカーテキストは、より多くの比重が置かれる。
・ある期間における変更度合(rate of change)が加速傾向か、減速傾向かが考慮される。
例えば、変更度合が増加傾向にあるページはスコアが高くなる。
・検索エンジンは、コンテンツの変更を検出するため、
①すべてのドキュメントそのものの代わりにドキュメントの「署名(signatures)」を格納することができる。
この場合検索エンジンは、ドキュメント(またはページ)に対する用語ベクトルを格納し、変更を監視できる。
②ドキュメントの要約等を格納し、変更を監視できる。
③ドキュメントに対し類似ハッシュを生成し、変更を監視できる。
③クエリ分析
検索エンジンは、ユーザーによって比較的頻繁に選択されている/ユーザーによる選択が増加しつつあるドキュメント(ページ)を、他よりも高くスコア付けすることができる。
・類似のクエリーによる検索結果数の著しい増加は、例えば、最新のトピックまたはニュース速報を示す。
この場合、そのようなクエリーに関連するドキュメントのスコアは上がり得る。
・ドキュメントの陳腐化は、例えば、ドキュメント作成日、アンカーの成長、トラフィック、コンテンツ変更、前方リンク/後方リンクの成長等といった要因に基づくことができる。
検索エンジンは、検索結果中のどのドキュメントがユーザーのよって選択されるかを分析することにより、どのクエリーの最近の変更が最も重要かを学習することができる。具体的には、検索エンジンは、検索結果のうち「古いドキュメントより低ランクにある新しいドキュメント」をユーザがどのくらい好むのかを考慮する。
ただし場合によっては、古いドキュメントは、より最近のドキュメントより好まれると考えられる。
④リンクベース基準
リンク要因は、ドキュメント(ページ)スコアの生成等に使用され得る。
・新しいリンクの数または比率の減少傾向は、ドキュメント(ページ)が古いというシグナルとなる。
この場合、検索エンジンはドキュメントのスコアを減少させ得る。
・時間経過に伴うドキュメント(またはページ)へのバックリンクの増加/減少の数または比率の変化を分析することにより、検索エンジンはドキュメントの新鮮さを導くことができる。
・各リンクは、リンクの新鮮度に伴い加重され得る。
・リンクは、リンクを包含するドキュメントの信頼度に基づいて加重され得る(例えば、政府ドキュメントは信頼度が高い)。
・リンクは、リンクを包含するドキュメントの権威性に基づいて加重され得る。
・ドキュメントへのリンクの年数分布(age distribution)により、検索エンジンはスコア付けし得る。
⑤アンカーテキスト
アンカーテキストの時間に伴う変化や新鮮度は、ドキュメントスコアの生成等に使用され得る。
・アンカーテキストの新鮮度は、例えば、アンカーテキストの出現/変更の日付、アンカーテキストに関連付けられたリンクの出現/変更の日付、リンクポイントに関連付けられたドキュメントの出現/変更の日付によって、決定され得る。
・優良なアンカーテキストは変更されないままという理論に基づき、リンクにポイントされたドキュメントの出現/変更の日付は、アンカーテキスト新鮮度の優良な指標となり得る。
⑥トラフィック
時間経過に伴うトラフィック情報は、ドキュメントスコアの生成等に使用され得る。
・検索エンジンは、トラフィックパターンの反復や、時間に伴うトラフィックパターンの変化を特定することが出来る。例えば、夏季期間中、週末、もしくはその他の季節などにおいて、トラフィックが多いまたは少ない期間が存在することが、見出され得る。
トラフィックパターンの反復または変化を特定することにより、検索エンジンは、これらの期間中内外で、ドキュメントのスコア付けを適切に調整することができる。
・検索エンジンは、特別のドキュメント(ページ)に対する「広告トラフィック」の時間依存的特徴を監視することができる。
・検索エンジンは、以下のファクターのうち1つまたはこれらの組み合わせを監視することができる。
(1)時間とともに既知のドキュメントによって広告が表示されたまたは更新された範囲、および、時間とともに既知のドキュメントによって広告が表示されたまたは更新された比率
(2)広告主の質
(3)広告が、関連するドキュメントに対するユーザー・トラフィックを生成する範囲(例えば、クリック率)
⑦ユーザーの行動
個人に対応する情報またはドキュメントに関連するユーザーの行動の集積は、ドキュメントスコアの生成等に使用され得る。
・検索エンジンは、ドキュメントが一連の検索結果から選択される回数や、ユーザーがドキュメントにアクセスするために費やす時間を監視することができる。
・ユーザーが同一または同類のクエリーを与えられたドキュメントの平均時間より多い時間または少ない時間を費やした場合、これはドキュメントが、それぞれ、新鮮であるかもしくは古くなったという指標として使用することができる。
例えば、「リバービュー・スイミング・スケジュール」というクエリーが「リバービュー・スイミング・スケジュール」というタイトルを伴うドキュメントを返すと仮定する。そしてユーザーは、以前そこにアクセスするのに30秒費やしたが、今はそこにアクセスするのに数秒だけしか費やさないと仮定する。
この場合検索エンジンは、このドキュメントは古くなった(すなわち、日にちが過ぎてしまったスイミング・スケジュールを包含する)と判断することができ、そのドキュメントを適切にスコア付けすることができる。
⑧ドメイン情報
ドメインに関連情報は、ドキュメントスコアの生成等に使用され得る。
・ドメインの合法性についての情報は、スコア付けを行う際に検索エンジンに使用され得る。
⑨ランキング履歴
ドキュメントの前回のランキングに関連する情報は、ドキュメントスコアの生成等に使用され得る。
・例えば検索エンジンは、ドキュメントの時間依存性ランキングを監視することができる。
多数のクエリーを通じてランキングが飛ぶように変動するドキュメントは、時事的なドキュメントか、または検索エンジンにスパミングをかけようという試みであると検索エンジンは判断できる。
⑩ユーザーによって保存/生成されたデータ
ユーザーが保持または生成するデータは、ドキュメントスコアの生成等に使用され得る。
・例えば、検索エンジンは、「ブックマーク」「お気に入り」等の、ユーザーが保持または生成するデータを監視することができる。
・検索エンジンは、直接的(例えば、ブラウザアシスタント)または間接的(例えば、ブラウザ)に、このデータを獲得することができる。
・検索エンジンは、ドキュメントの重要性を決定するためにドキュメントが関連付けられたブックマーク/お気に入りの数を時間とともに分析することができる。
⑪アンカーテキスト中のユニークワード、バイグラム、フレーズ
アンカーテキスト中のユニークワード、バイグラム、フレーズは、ドキュメントスコアの生成等に使用され得る。
例えば、検索エンジンは、時間に伴うウェブ(またはリンク)・グラフおよびその振る舞いを監視することができ、さらに、この情報をスコア付け、スパム検出、またはその他の目的のために使用することができる。
⑫独立したドキュメント(ページ)からのリンク/(ページ)への リンク
独立したドキュメントのリンクに関する情報は、ドキュメントスコアの生成等に使用され得る。
個々のドキュメントの大量の出入りを伴った、独立したドキュメントの数の急成長は、スパムへの意図の指標となる潜在合成ウェブ・グラフを示すことができる。
⑬ドキュメントトピックス
ドキュメントのトピックスは、ドキュメントスコアの生成等に使用され得る。
・例えば検索エンジンは、(カテゴリー化・URL分析・コンテンツ分析・クラスタリング・要約化・一連の特有な低頻度用語、もしくはその他のタイプのトピック抽出を通して)トピック抽出を実行することができる。検索エンジンは、時間とともにドキュメントトピックを監視し、またスコア付け目的のためにこの情報を使用することができる。
☆ ☆ ☆
長くなりましたが、ページランク(ランキングアルゴリズム)に関するGoogleの特許公報でした。
SEOに興味のある方の参考になれば幸いです。
最後に本特許公報のまとめです。
・ランキングスコアは、ヒストリデータに(一部)基づいて算出される
・ヒストリデータには、ドキュメント(ページ)作成日、コンテンツの更新/変更、クエリ分析、リンクベース基準、アンカーテキスト、トラフィック、ユーザーの行動、ドメイン情報、ランキング履歴、ユーザー保存データ、トピックスなどを含む